

Driven by the desire to shrink to zero the time it takes to turn massive volumes of raw data into useful information and action, streaming is deceptively simple: just process and act on data as it arrives, quickly, and in a continuous and infinite fashion.
For use cases from Industrial IoT to Connected Cars to Real-Time Fraud Detection and more, we’re increasingly looking to build new applications and customer experiences that react quickly to customer interests and actions, learn and adapt to changing behavior patterns, and the like. But the reality is most of us don’t yet have the tools to do this with production level data volumes, ingestion rates, and fault resiliency. So we do the best we can with bespoke systems piling complexity on top of complexity.
Complexity is symptomatic of fundamental systems design mismatches: we’re using a component for something it wasn’t designed to do, and the mechanisms at our disposal won’t scale from small to large.
Streaming is hard at scale because it assumes three disruptive systems capabilities:
- Ability to treat data as continuous and infinite rather than finite and static
- Ability to deliver consistently fast results by dynamically scaling data ingest, storage, and processing capacity in coordination with the volume of data arriving
- Ability to deliver accurate results processing data continuously even with late arriving or out of order data
Here’s where it gets interesting and even more disruptive, in a good way: the streaming paradigm of event-driven, continuous, and stateful data processing along with its coherent understanding of time in many cases is more efficient and powerful than a traditional ETL > Store > Query approach even for applications that do not have real-time requirements!

Streaming is forcing systems designers to rethink fundamental computational and storage principles. As passionate storage people, we’re doing our part by designing a new storage primitive, called a stream, purpose-built for streaming architecture and implemented in a new open source project named Pravega.
By combining Pravega streaming storage with a stateful stream processor like Apache Flink, we realize a system where all the elements in the picture above – writers, processors, readers, and storage – are independently, elastically, and dynamically scalable in coordination with the volume of data arriving enabling all of us to build streaming apps we could not before, and to seamlessly scale them from prototype to production.
Streaming Storage Requirements
Let’s look at each of the three disruptive characteristics of a streaming system and see how Pravega streams enable them in ways not possible with today’s storage.
Treat Data as Continuous and Infinite
While appending to the end of a file and tailing its contents emulates a continuous and infinite flow of data, files are not optimized for this pattern. Nor are they infinite. Anyone who has ever rotated log files knows this. Sockets or pipes are a better abstraction for continuous data, but they are not durable. Messaging is a reasonable abstraction for continuous data – especially something like Kafka’s append-only log – but they are not designed as infinite, durable systems. And they impose data structure with envelopes and headers making them not as general purpose as a byte sequence.
Stitching these ideas together, we come up with the characteristics Pravega will support from the perspective of data as continuous and infinite:
- A Pravega stream is a named, durable, append-only, infinite sequence of bytes
- With low-latency appends to and reads from the tail of the sequence
- With high-throughput catch-up reads from older portions of the sequence

System Scaling Based on Data Arrival Volume
So how do we elastically yet independently scale data ingest, storage, and data processing based on data volume?
We get parallelism by splitting data into partitions, and processing each independently. Hadoop, for example, implemented this for batch with HDFS and map-reduce. For streaming-style workloads, we’d do it today with queues or Kafka partitions. Both of these options have the same problem: the partitioning impacts both readers and writers. Read/write scaling requirements for continuous processing often differ, and linking them adds complexity. Furthermore, while you can add queues or partitions to scale, this requires manual, coordinated updates to writers, readers, and storage. This is complex and not dynamic scaling.
Pravega streams, designed for dynamic and independent scaling, support:
- Many writers simultaneously appending a disjoint subset of data
- A disjoint subset is defined by data written with the same key
- Assigning keys to writers is left to the app – the storage must not constrain nor require change when the key space or writers changes
- Many readers simultaneously processing a disjoint subset of data
- Data partitioning for reads must be independent of write partitioning
- Read partitioning must be controlled by storage policy, e.g. split a stream into enough segments to ensure none sees more than N bytes/sec
- The number of segments in a stream must be automatically and continuously updated by the storage system per incoming data volume
These are tough requirements. Let’s examine two typical partitioning schemes.
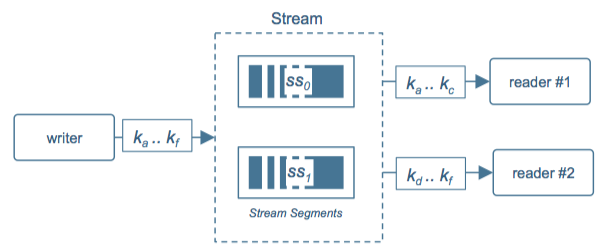
In Figure 3, processing is longer than ingest. There is one writer, but data is segmented for reads: reader #1 gets data for keys ka .. kc, and the other gets keys kd .. kf. In Figure 4, processing is faster than ingest so the topology inverts: multiple writers partition the key space for writes, but one reader processes it.
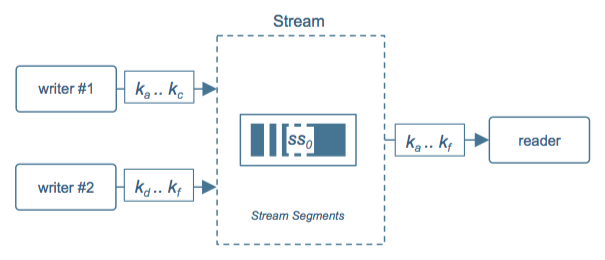
In real life, we end up somewhere in between – likely shifting over time as our data sources and apps evolve. While a stream would be comprised internally of multiple segments, (a) writers are unaware of the segment topology as they just know about keys, and (b) readers learn the segment topology dynamically – just point them at a stream and go.
In order for the overall system (storage + processing) to adapt to changing data volumes, Pravega continually monitors a stream’s incoming data rate and ensures the proper number of segments exist to meet SLO compliance. Figure 5 illustrates a stream’s segments dynamically changing over time.
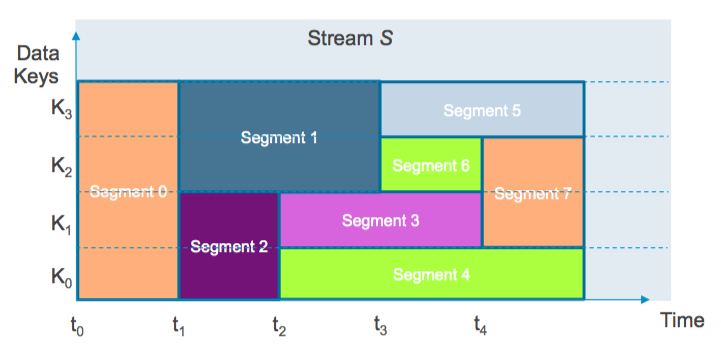
At t0, the incoming data rate is below the scaling SLO. All data is stored in Segment 0. At t1, the SLO is exceeded. Segment 0 is sealed, and Segments 1 and 2 are created. New data for k0 and k1 will go to Segment 2. New data for k2 and k3 goes to Segment 1. This is a segment split in response to volume increase. Splitting also occurs at t2 and t3.
At t4, the rate slows. Segments 3 and 6 are sealed, and Segment 7 is created and will hold new data for k1 .. k2. This is a segment merge in response to volume decrease.
Pravega’s segment scaling protocol allowing readers to track segment scaling and to take appropriate action, e.g. to add or remove readers, enabling the system as a whole to dynamically scale in a coordinated fashion.

Produce Accurate Results Processing Data Continuously
Computing accurate results continuously implies exactly once processing, and distinguishing event time – the time something occurred in real life – from processing time – when the data about that occurrence is processed computationally. To this we add a requirement to chain apps while preserving exactly once to split a computation into multiple, independent apps. This is streaming meets micro-services.
A streaming system that produces accurate results leads to major cost savings compared to lambda architecture where real-time and batch processing use separate infrastructures. Not only is this simpler and cheaper – it’s one infrastructure instead of two – it simplifies development as you code once rather than once per infrastructure in lambda. There is a terrific write up of these concepts in Tyler Akidau’s O’Reilly blog entitled, The world beyond batch: Streaming 101.
The storage requirements for exactly once are clear: streams must be durable, ordered, consistent, and transactional. These are critical attributes because they are the most difficult aspects of storage system design. You can’t change them later without a major redesign.
Durability implies that once acknowledged, a write will never get lost even in the face of component failure. Durability is essential to exactly once because if data is lost, it cannot be (re)processed. Data that is mostly durable doesn’t cut it: either you can depend on storage for durability or you can’t. A system that is not durable is not a system of record meaning a permanent copy of the data must be stored elsewhere – often in archive systems like object storage or NAS. Archiving means app code for ETL and management of ETL processes. This complexity is eliminated because Pravega streaming storage is a durable, permanent store where you can reliably keep your stream data forever.
Ordering implies readers will process data in the same order it is written. For systems like streams with key-partitioned writes, ordering is meaningful only with respect to data with the same key. In an IoT system with millions of devices generating sensor metrics, the sensor-ID.metric might be a key. A stream guarantees reads of a key’s data will come in the same order it was written. Ordering is essential for many computations such as aggregate metrics computed using delta updates.
Consistency means that all readers will see the same ordered view of data for a given key – even in the face of component failure – whether data is read from the tail of the stream or via catch-up reads. As with durability, mostly consistent doesn’t cut it: either the storage is consistent or it is not. From the perspective of exactly once requirements, storage consistency is as important as distinguishing event time vs. processing time in the computation layer.
Transactional writes are necessary for exactly once across chained applications. Stateful stream processors like Flink have internal mechanisms for exactly once within a single app using clever distributed checkpoints. Extending the scope of exactly once across multiple apps requires the intermediate storage, streams in our case, to participate in these checkpoint schemes via transactional writes.
Introducing Pravega Streams
Pravega is an open source distributed storage service implementing streams. A stream is the foundation for reliable streaming systems: a high-performance, durable, elastic, and infinite append-only byte stream with strict ordering and consistency.
A stream is lightweight. Just like files or objects, we can quickly and easily create as many of them as we need – on the order of millions in a single cluster.
By refactoring and externalizing previously internal and proprietary logs, streams greatly simplify the development and operation of a new generation of distributed middleware reimagined as streaming infrastructure:
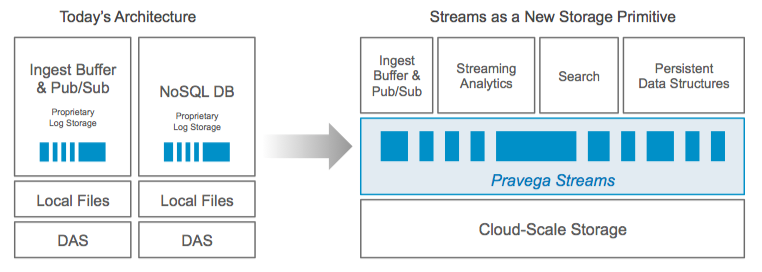
The Pravega project currently includes the Pravega byte stream primitive plus a layered ingest buffer and pub/sub mechanism, similar in concept to Kafka, but with streaming characteristics for performance, elasticity, infiniteness, consistency, and durability. We’ll discuss integration of Pravega’s ingest buffer with Flink in the next section.
Two other projects, both reimagining common middleware services as streaming infrastructure, are in early conceptual stages:
- Stream-based full-text search: a dynamic, distributed, real-time Lucene indexer with continuous query facilities for stream data
- Stream-backed persistent data structures: a framework for micro-services purists who want their micro-services to own their own data
Stay tuned to this blog space for more information about those projects!
Pravega Architecture
Pravega’s architecture has three main components. The Pravega Streaming Service is a distributed software service implementing the stream abstraction semantics including the stream control and segment store APIs, data memory caching (using Rocks DB), and data placement and tiering logic utilizing two underlying storage systems: low-latency storage with Apache Bookkeeper, and high-throughput, high-scale storage currently using a backing HDFS. [This component is designed to be pluggable to support alternate backing storage systems with appropriate strong consistency semantics.]
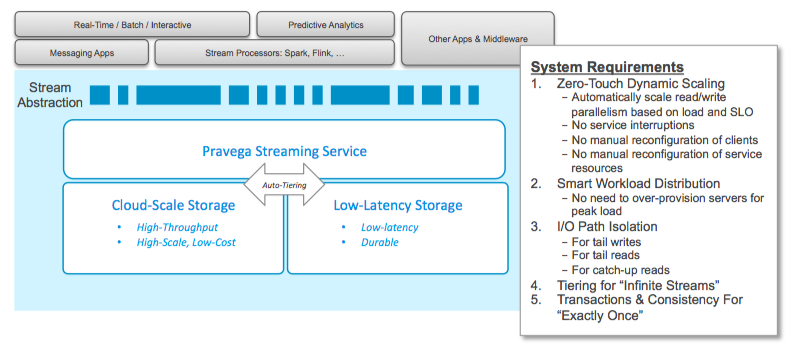
There are many innovations in Pravega’s system design enabling it to meet a stream’s challenging requirements. The I/O path design completely isolates the read and write paths enabling extremely low-latency durable writes to the tail, low-latency reads from the tail, and high-throughput reads from the older portion of the stream. The detail of Pravega’s architecture is beyond the scope of this write up. More information is available in the Pravega Architecture Wiki.
Streaming Storage + Apache Flink = YEAH!
Let’s explore how Pravega streams integrate with Flink to realize a dynamic and elastic system delivering fast and accurate computational results while processing massive data volumes in constant time even with widely varying data rates.
The system’s conceptual structure is shown in Figure 9. It contains a typical input stream with raw data written by a fleet of writers, a multi-worker Flink app to process it, and a chained Flink app that processes the output of the first.
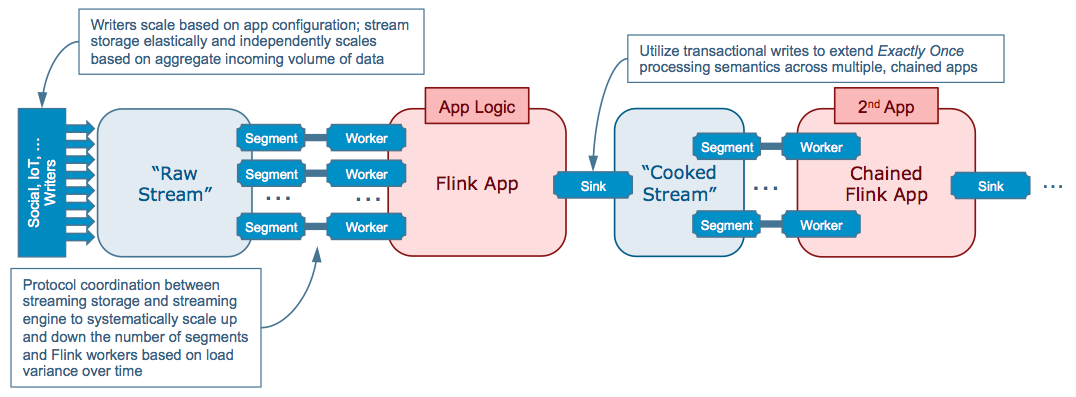
Here’s where this is different: every element – writers, input stream, reader app, output stream – are independently, elastically, and dynamically scalable in response to variations in data volume arrival rate over time.
Two integration points enable this: Pravega’s segment scaling driving Flink’s worker scaling, and chaining apps via streams preserving exactly once across the system. Deploy your Flink app with just one worker, and dynamically scale it based on stream SLO. Nice! Pravega and Flink developers are already integrating stream auto-scaling into Flink.
Beyond this goodness, an infinite stream significantly simplifies many operational use cases. Let’s consider rolling out a new version of your Flink app (any app, really) where you first want to test it against historical data.
Figure 10 shows a typical deployment today for a real-time Flink app. Information is fed into a messaging system, processed by a Flink app, and then forwarded to a NOC or similar framework for display and/or action. In parallel, ETL workers continuously pull messages and write them to a durable store for historical access.
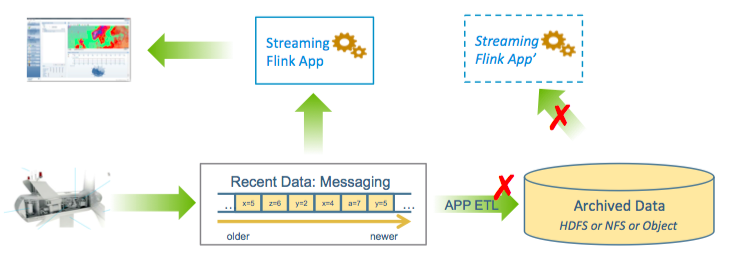
Now we’ve built a new version of our app, App’. What is the operational procedure to try the new logic against historical data sets to validate correctness and ensure no regression before deploying, non-disruptively, into production?
First, we need to deploy App’ to get its data from the archive rather than the messaging system. So your test is not quite like production: subtle behavioral differences between archive and messaging may make the test unreliable. When testing completes, we then re-deploy App’ to use the messaging system, and re-prime its caches or other state derived from historical data. If all works, we can finally replace the prior version. The result is a complex workflow sequence. And complexity means trouble.
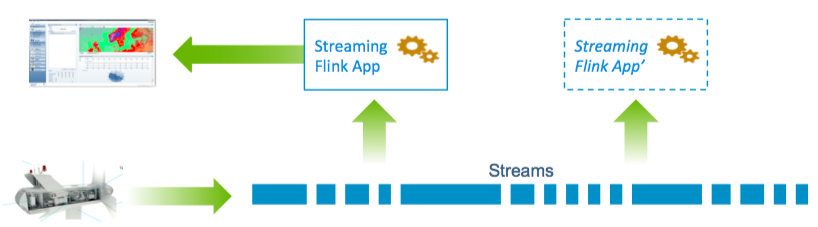
How does this change with Pravega streams? App’ is deployed exactly like production since historical data is accessed via the same stream – just rewind it! When history is consumed, App’ and App are processing the same data with the same state. When we are confident App’ is good, turn off App and redirect the NOC. Sweet!
Closing Thoughts
For those that made it to the end … thank you for your patience! We’re passionate storage people, and we like to view problems through the lens of how the right storage construct can aid in solving them. We love the idea of streaming. We are excited about computing technologies like Flink that were “born streaming.” We think the world needs a complementary storage technology that is born streaming. Pravega is our contribution. We believe it will further the state-of-the-art in streaming making its benefits easily accessible to anyone.
Remember, when you think of streaming apps, think of data as continuous and infinite rather than static and finite. And think of the importance of enterprise storage qualities like durability, consistency, elasticity, and now, infiniteness (is that a word?).
Please check back to this blog often to keep up with new concepts and ideas related to Pravega’s mission to reimagine data middleware as streaming infrastructure. If you, too, are passionate about this, we encourage you to join our community!
About the Author

Salvatore DeSimone – VP and CTO Advanced Software Division at Dell EMC