Pravega Segment Store Service¶
- Introduction
- Terminology
- Architecture
- Components
- Integration with Controller
- Storage Abstraction
- Data Flow
Introduction¶
The Pravega Segment Store Service is a subsystem that lies at the heart of the entire Pravega deployment. It is the main access point for managing Stream Segments, providing the ability to create, delete and modify/access their contents. The Pravega client communicates with the Pravega Stream Controller to figure out which Stream Segments need to be used (for a Stream), and both the Stream Controller and the client deal with the Segment Store Service to operate on them.
The basic idea behind the Segment Store Service is that it buffers the incoming data in a very fast and durable append-only medium (Tier 1), and syncs it to a high-throughput (but not necessarily low latency) system (Tier 2) in the background, while aggregating multiple (smaller) operations to a Stream Segment into a fewer (but larger) ones.
The Pravega Segment Store Service can provide the following guarantees:
- Stream Segments that are unlimited in length, with append-only semantics, yet supporting arbitrary-offset reads.
- No throughput degradation when performing small appends, regardless of the performance of the underlying Tier 2 Storage system.
- Multiple concurrent writers to the same Stream Segment.
- the order is guaranteed within the context of a single Writer, but appends from multiple concurrent Writers will be added in the order in which they were received (appends are atomic without interleaving their contents).
- Writing to and reading from a Stream Segment concurrently with relatively low latency between writing and reading.
Terminology¶
The following terminologies are used throughout the document:
- Stream Segment or Segment: A contiguous sequence of bytes, similar to a file of unbounded size. This is a part of a Stream, limited both temporally and laterally (by key). The scope of Streams and mapping Stream Segments to such Streams is beyond the purpose of this document.
- Tier 2 Storage or Permanent Storage: The final resting place of the data.
- Tier 1 Storage: Fast append storage, used for durable buffering of incoming appends before distributing to Tier 2 Storage.
- Cache: A key-value local cache with no expectation of durability.
- Pravega Segment Store Service or Segment Store: The Service that this document describes.
- Transaction: A sequence of appends that are related to a Segment, which, if persisted, would make up a contiguous range of bytes within it. This is used for ingesting very large records or for accumulating data that may or may not be persisted into the Segment (but its fate cannot be determined until later in the future).
Note: At the Pravega level, a Transaction applies to an entire Stream. In this document, a Transaction applies to a single Segment.
Architecture¶
The Segment Store is made up of the following components:
- Pravega Node: A host running a Pravega Process.
- Stream Segment Container (or Segment Container): A logical grouping of Stream Segments. The mapping of Segments to Containers is deterministic and does not require any persistent store; Segments are mapped to Containers via a hash function (based on the Segment's name).
- Durable Data Log Adapter (or Durable Data Log): An abstraction layer for Tier 1 Storage.
- Storage Adapter: An abstraction layer for Tier 2 Storage.
- Cache: An abstraction layer for append data caching.
- Streaming Client: An API that can be used to communicate with the Pravega Segment Store.
- Segment Container Manager: A component that can be used to determine the lifecycle of Segment Containers on a Pravega Node. This is used to start or stop Segment Containers based on an external coordination service (such as the Pravega Controller).
The Segment Store handles writes by first writing them to a log (Durable Data Log) on a fast storage (SSDs preferably) and immediately acking back to the client after they have been persisted there. Subsequently, those writes are then aggregated into larger chunks and written in the background to Tier 2 Storage. Data for appends that have been acknowledged (and are in Tier 1) but not yet in Tier 2 is stored in the Cache (in addition to Tier 1). Once such data has been written to Tier 2 Storage, it may or may not be kept in the Cache, depending on a number of factors, such as Cache utilization/pressure and access patterns.
More details about each component described above can be found in the Components section.
System Diagram¶
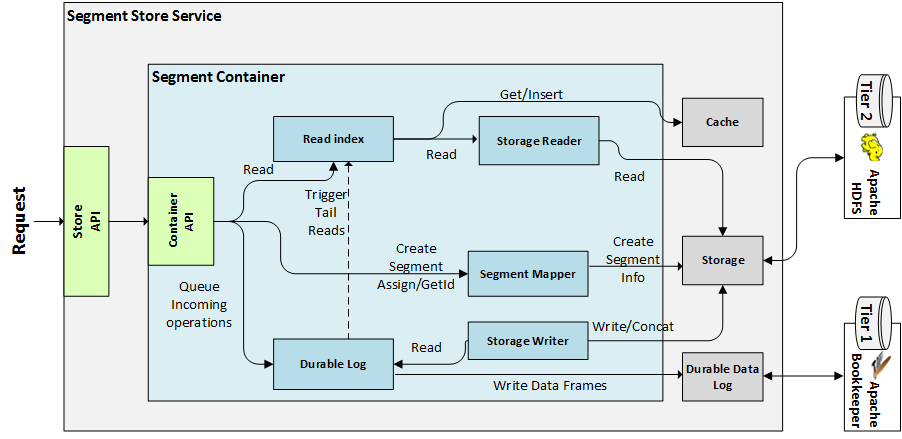
In the above diagram, the major components of the Segment Store are shown. But for simplicity, only one Segment Container is depicted. All Container components and major links between them (how they interact with each other) are shown. The Container Metadata component is not shown, because every other component communicates with it in one form or another and adding it would only clutter the diagram.
More detailed diagrams can be found under the Data Flow section.
Components¶
Segment Containers¶
Segment Containers are a logical grouping of Segments and are responsible for all operations on those Segments within their span. A Segment Container is made of multiple sub-components:
- Segment Container Metadata: A collection of Segment-specific metadata that describes the current state of each Segment (how much data in Tier 2, how much in Tier 1, whether it is sealed, etc.), as well as other miscellaneous info about each Container.
- Durable Log: The Container writes every operation it receives to this log and acks back only when the log says it has been accepted and durably persisted.
- Read Index: An in-memory index of where data can be read from. The Container delegates all read requests to it, and it is responsible for fetching the data from wherever it is currently located (Cache, Tier 1 Storage or Tier 2 Storage).
- Cache: Used to store data for appends that exist in Tier 1 only (not yet in Tier 2), as well as blocks of data that support reads.
- Storage Writer: Processes the durable log operations and applies them to Tier 2 Storage (in the order in which they were received). This component is also the one that coalesces multiple operations together, for better back-end throughput.
Segment Container Metadata¶
The Segment Container Metadata is critical to the good functioning and synchronization of its components. This metadata is shared across all components and it comes at two levels: "Container-wide metadata" and "per-Segment metadata". Each serves a different purpose and is described below.
Container Metadata¶
Each Segment Container needs to keep some general-purpose metadata that affects all operations inside the container:
- Operation Sequence Number: The largest sequence number assigned by the Durable Log. Every time a new operation is received and successfully processed by the Durable Log, this number is incremented (its value will never decrease or otherwise rollback, even if an operation failed to be persisted).
- The operation sequence number is guaranteed to be strict-monotonic increasing (no two operations have the same value, and an operation will always have a larger sequence number than all operations before it).
- Epoch: A number that is incremented every time a successful recovery (Container Start) happens. This value is durably incremented and stored as part of recovery and can be used for a number of cases (a good use is Tier 2 fencing for HDFS, which doesn't provide a good, native mechanism for that).
- Active Segment Metadata: Keeps information about each active Stream Segment. A Segment is active if it has had activity (read or write) recently and is currently loaded in memory. If a Stream Segment is idle for a while, or if there are many Stream Segments currently active, a Stream Segment becomes inactive by having its outstanding metadata flushed to Tier 2 Storage and evicted from memory.
- Tier 1 Metadata: Various pieces of information that can be used to accurately truncate the Tier 1 Storage Log once all operations prior to that point have been durably stored to Tier 2.
- Checkpoints: Container metadata is periodically Checkpointed by having its entire snapshot (including Active Segments) serialized to Tier 1. A Checkpoint serves as a Truncation Point for Tier 1, as it contains all the updates that have been made to the Container via all the processed operations before it, so we no longer need those operations in order to reconstruct the metadata. If we truncate Tier 1 on a Checkpoint, then we can use information from Tier 2 and this Checkpoint to reconstruct by using the previously available metadata, without relying on any operation prior to it in Tier 1.
Segment Metadata¶
Each Segment Container needs to keep per-segment metadata, which it uses to keep track of the state of each segment as it processes operations for it. The metadata can be volatile (it can be fully rebuilt upon recovery) and contains the following properties for each segment that is currently in use:
Name: The name of the Stream Segment.Id: Internally assigned unique Stream Segment ID. This is used to refer to Stream Segments, which is preferred to the Name. This ID is used for the entire lifetime of the Stream Segment, which means that even if the Stream Segment becomes inactive, a future reactivation will have it mapped to the same ID.StartOffset(also known asTruncationOffset): The lowest offset of the data that is available for reading. A non-truncated Stream Segment will have Start Offset equal to 0, while subsequent Truncate operations will increase (but never decreases) this number.StorageLength: The highest offset of the data that exists in Tier 2 Storage.Length: The highest offset of the committed data in Tier 1 Storage.LastModified: The timestamp of the last processed (and acknowledged) append.IsSealed: Whether the Stream Segment is closed for appends (this value may not have been applied to Tier 2 Storage yet).IsSealedInStorage: Whether the Stream Segment is closed for appends (and this has been persisted in Tier 2 Storage).IsMerged: Whether the Stream Segment has been merged into another one (but this has not yet been persisted in Tier 2 Storage). This only applies for Transactions. Once the merge is persisted into Tier 2, the Transaction Segment does not exist anymore (soIsDeletedwill become true).IsDeleted: Whether the Stream Segment is deleted or has recently been merged into another Stream Segment. This only applies for recently deleted Stream Segments, and not for Stream Segments that never existed.
The following are always true for any Stream Segment:
StorageLength<=LengthStartOffset<=Length
Log Operations¶
The Log Operation is a basic unit that is enqueued in the Durable Log. It does not represent an action, per se, but is the base for several serializable operations (we can serialize multiple types of operations, not just Appends). Each operation is the result of an external action (which denote the alteration of a Stream Segment), or an internal trigger, such as metadata maintenance operations.
Every Log operation has the following elements:
SequenceNumber: The unique sequence number assigned to this entry (see more under Container Metadata) section.
The following are the various types of Log operations:
- Storage Operations: Represent operations that need to be applied to the underlying Tier 2 Storage:
StreamSegmentAppendOperation: Represents an append to a particular Stream Segment.CachedStreamSegmentAppendOperation: Same asStreamSegmentAppendOperation, but this is for internal use (instead of having an actual data payload, it points to a location in the Cache from where the data can be retrieved).StreamSegmentSealOperation: When processed, it sets a flag in the in-memory metadata that no more appends can be received. When the Storage Writer processes it, it marks the Stream Segment as read-only in Tier 2 Storage.StreamSegmentTruncateOperation: Truncates a Stream Segment at a particular offset. This causes the Stream Segment'sStartOffsetto change.MergeTransactionOperation: Indicates that a Transaction is to be merged into its parent Stream Segment.
- Metadata Operations are auxiliary operations that indicate a change to the Container metadata. They can be the result of an external operation (we received a request for a Stream Segment we never knew about before, so we must assign a "unique ID" to it) or to snapshot the entire metadata (which helps with recovery and cleaning up Tier 1 Storage). The purpose of the metadata operations is to reduce the amount of time needed for failover recovery (when needed).
StreamSegmentMapOperation: Maps an ID to a Stream Segment Name.TransactionMapOperation: Maps an ID to a Transaction and to its Parent Segment.UpdateAttributesOperation: Updates any attributes on a Stream Segment.MetadataCheckpoint: Includes an entire snapshot of the metadata. This can be useful during recovery. This contains all metadata up to this point, which is a sufficient base for all operations after it.
Durable Log¶
The Durable Log is the central component that handles all Log operations. All operations (which are created by the Container) are added to the Durable Log, which processes them in the order in which they were received. It is made up of a few other components, all of which are working towards a single goal of processing all incoming operations as quickly as possible, without compromising data integrity.
Information Flow in the Durable Log¶
- All received operations are added to an Operation Queue (the caller receives a Future which will be completed when the operation is durably persisted).
- The Operation Processor picks all operations currently available in the queue (if the queue is empty, it will wait until at least one operation is added).
-
The Operation Processor runs as a continuous loop (in a background thread), and executes the following steps.
-
Dequeue all outstanding operations from the operation Queue (described above).
-
Pre-process the operations (validate that they are correct and would not cause undesired behavior, assign offsets (where needed), assign sequence numbers, etc.)
-
Write the operations to a Data Frame Builder, which serializes and packs the operations in Data Frames. Once a Data Frame is complete (full or no more operations to add), the Data Frame Builder sends the Data Frame to the Durable Data Log. Note that, an operation may span multiple DataFrames, but the goal is to make the best use of the Durable Data Log throughput capacity by making writes as large as possible considering the maximum size limit per write.
-
-
When a Data Frame has been durably persisted in the Durable Data Log, the operation Processor post-processes all operations that were fully written so far. It adds them to in-memory structures, updates indices, etc., and completes the Futures associated with them.
-
The Operation Processor works asynchronously, by not waiting for a particular Data Frame to be written before starting another one and sending it to the Durable Data Log. Likewise, multiple Data Frames may be in flight by maintaining a specific order. The operation Processor relies on certain ordering guarantees from the Durable Data Log, if a particular Data Frame was acked, it assures that all the prior Data Frames to it were also committed successfully, in the right order.
Note: The operation Processor does not do any write throttling. It leaves that to the Durable Data Log implementation, but it controls the size of the Data Frames that get sent to it.
Truncation¶
Based on supplied configuration, the Durable Log auto-adds a special kind of operation, named MetadataCheckpointOperation. This operation, when processed by the operation Processor, collects a snapshot of the entire Container metadata and serializes it to the Durable Data Log. This special operation marks a Truncation Point - a place in the Stream of Log operations where we can issue Truncate operations. It is very important that after every truncation, the first operation to be found in the log is a MetadataCheckpointOperation, because without the prior operations to reconstruct metadata, this is the only way to be able to process subsequent operations.
Note: Durable Data Log (Tier 1) truncation should not be confused with Segment Truncation. They serve different purposes and are applied to different targets.
Operation Processor¶
The Operation Processor is a sub-component of the Durable Log that deals with incoming Log operations. Its purpose is to validate, persist, and update metadata and other internal structures based on the contents of each operation.
Operation Metadata Updater¶
The Operation Metadata Updater is a sub-component of the Durable Log that is responsible with validating operations based on the current state of the metadata, as well as update the metadata after a successful commit of an operation. Internally it has various mechanisms to handle failures, and it can rollback certain changes in failure situations.
Durable Data Log¶
The Durable Data Log is an abstraction layer to an external component that provides append-only semantics. It is supposed to be a system which provides very fast appends to a log, that guarantees the durability and consistency of the written data. The read performance is not so much a factor, because we do not read directly from this component. Read is performed on it when we need to recover the contents of the Durable Log.
As explained above, Log operations are serialized into Data Frames (with a single operation able to span multiple such Frames if needed), and these Data Frames are then serialized as entries into this Durable Data Log. This is used only as a fail-safe, and we only need to read these Frames back if we need to perform recovery (in which case we need to deserialize all Log operations contained in them, in the same order in which they were received).
In-Memory Operation Log¶
The In-Memory Operation Log contains committed (and replicated) Log operations in the exact same order as they were added to the Durable Data Log. While the Durable Data Log contains a sequence of Data Frames (which contain serializations of operations), the Memory Log contains the actual operations, which can be used throughout the Durable Log and the Storage Writer.
The Memory Log is essentially a chain of Log operations ordered by the time when the operation was received. We always add at one end, and we remove from the other. When we truncate the Durable Data Log the Memory Log is also truncated at the same location.
Read Index¶
The Read Index helps the Segment Container perform reads from Streams at arbitrary offsets. While the Durable Log records (and can only replay) data in the order in which it is received, the Read Index can access the data in a random fashion. The Read Index is made of multiple Segment Read Indices (one per live Segment).
The Segment Read Index is a data structure that is used to serve reads from memory, as well as pull data from Tier 2 Storage and provides Future Reads (tail reads) when data is not yet available. When a read request is received, the Segment Read Index returns a read iterator that will return data as long as the read request parameters have not yet been satisfied. The iterator will either fetch data that is immediately available in memory, or request data from Tier 2 storage (and bring it to memory) or, if it reached the current end of the Segment, return a Future that will be completed when new data is added (thus providing tailing or future reads).
At the heart of the Segment Read Index lies a sorted index of entries (indexed by their start offsets) which is used to locate the requested data when needed. The index itself is implemented by a custom balanced binary search tree (AVL Tree to be more precise) with a goal of minimizing memory usage while not sacrificing insert or access performance. The entries themselves do not contain data, rather some small amount of metadata that is used to locate the data in the Cache and to determine usage patterns (good for cache evictions).
Cache¶
The Cache is a component where all data (whether from new appends or that was pulled from Tier 2 storage) is stored. It is a direct memory store entirely managed by the Read Index.
Storage Writer¶
Pravega is by no means the final resting place of the data, nor it is meant to be a storage service. The Tier 2 Storage is where we want data to be in the long term and Pravega is only used to store a very short tail-end of it (using Tier 1 Storage), enough to make appends fast and aggregate them into bigger chunks for committal to Tier 2 Storage. To perform this, it needs another component (Storage Writer) that reads data from the Durable Log in the order in which it was received, aggregates it, and sends it to Tier 2 Storage.
Just like the Durable Log, there is one Storage Writer per Segment Container. Each Writer reads Log operations from the in-memory operation Log (exposed via the read() method in the Durable Log) in the order they were processed. It keeps track of the last read item by means of its sequence number. This state is not persisted, and upon recovery, it can just start from the beginning of the available Durable Log.
The Storage Writer can process any Storage operation (Append, Seal, Merge), and as Pravega being the sole actor it modifies such data in Tier 2 and applies them without any constraints. It has several mechanisms to detect and recover from possible data loss or external actors modifying data concurrently.
Integration with Controller¶
Methods for mapping Segment Containers to hosts and rules used for moving from one to another are beyond the scope of this document. Here, we just describe how the Segment Store Service interacts with the Controller and how it manages the lifecycle of Segment Containers based on external events.
Segment Container Manager¶
Each instance of a Segment Store Service needs a Segment Container Manager. The role of this component is to manage the lifecycle of the Segment Containers that are assigned to that node (service). It performs the following duties:
- Connects to the Controller Service-Side Client (i.e., a client that deals only with Segment Container events, and not with the management of Streams and listens to all changes that pertain to Containers that pertain to its own instance.
- When it receives a notification that it needs to start a Segment Container for a particular Container Id, it initiates the process of bootstrapping such an object. It does not notify the requesting client of success until the operation completes without error.
- When it receives a notification that it needs to stop a Segment Container for a particular Container Id, it initiates the process of shutting it down. It does not notify the requesting client of success until the operation completes without error.
- If the Segment Container shuts down unexpectedly (whether during Start or during its normal operation), it will not attempt to restart it locally; instead it will notify the Controller.
Storage Abstractions¶
The Segment Store was not designed with particular implementations for Tier 1 or Tier 2. Instead, all these components have been abstracted out in simple, well-defined interfaces, which can be implemented against any standard file system (Tier 2) or append-only log system (Tier 1).
Possible candidates for Tier 1 Storage:
- Apache BookKeeper (preferred, adapter is fully implemented as part of Pravega)
- Non-durable, non-replicated solutions:
- In-Memory (Single node deployment only - Pravega becomes a volatile buffer for Tier 2 Storage; data loss is unavoidable and unrecoverable from in the case of process crash or system restart).
- This is used for unit test only.
- Local File System (Single node deployment only - Pravega becomes a semi-durable buffer for Tier 2 Storage; data loss is unavoidable and unrecoverable from in the case of complete node failure)
- In-Memory (Single node deployment only - Pravega becomes a volatile buffer for Tier 2 Storage; data loss is unavoidable and unrecoverable from in the case of process crash or system restart).
Possible candidates for Tier 2 Storage:
- HDFS (Implementation available)
- Extended S3 (Implementation available)
- NFS (general FileSystem) (Implementation available)
- In-Memory (Single node deployment only - limited usefulness; data loss is unavoidable and unrecoverable from in the case of process crash or system restart)
- This is used for unit test only.
A note about Tier 2 Truncation:
- The Segment Store supports Segment truncation at a particular offset, which means that, once that request is complete, no offset below that one will be available for reading.
- The above is a metadata update operation, however this also needs to be supported by Tier 2 so that the truncated data is physically deleted from it.
- If a Tier 2 implementation does not natively support truncation from the beginning of a file with offset preservation (i.e., a Segment of length 100 is truncated at offset 50, then offsets 0..49 are deleted, but offsets 50-99 are available and are not shifted down), then the Segment Store provides a wrapper on top of a generic Tier 2 implementation that can do that.
- The
RollingStorageTier 2 wrapper splits a Segment into multiple Segment Chunks and exposes them as a single Segment to the upper layers. Segment Chunks that have been truncated out, are deleted automatically. This is not a very precise application (since it relies heavily on a rollover policy dictating granularity), but it is a practical solution for those cases when the real Tier 2 implementation does not provide the features that we need.
Data Flow¶
Here are a few examples of how data flows inside the Pravega Segment Store Service.
Appends¶
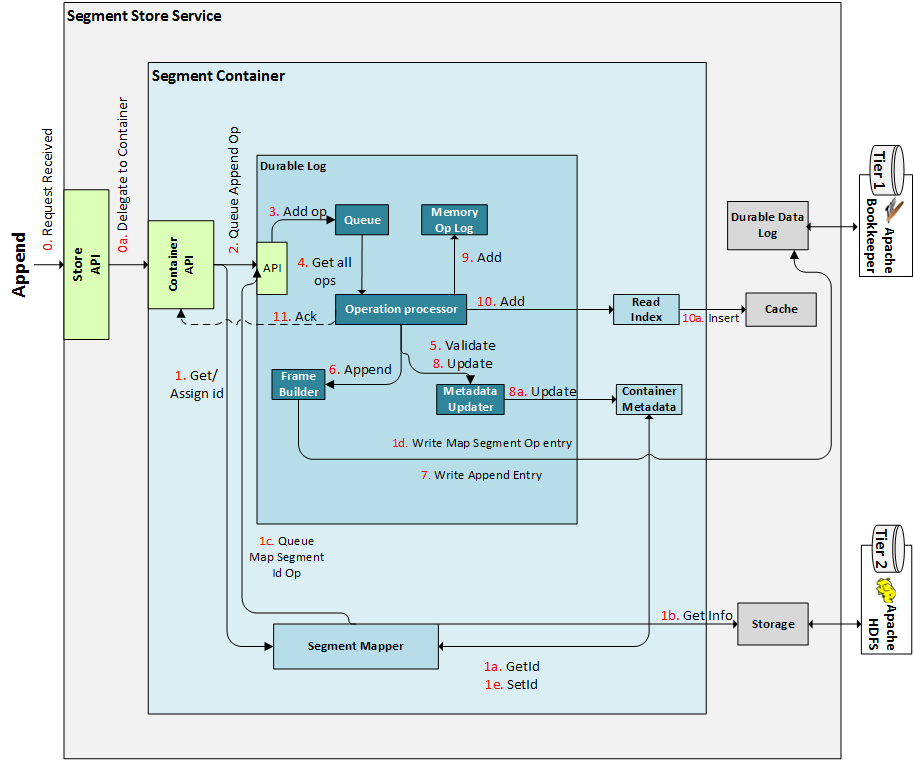
The diagram above depicts these steps (note the step numbers may not match, but the order is the same):
- Segment Store receives append request with params: Segment Name, Payload and Attribute Updates.
- Segment Store determines the Container ID for the given Segment and verifies that the Segment Container is registered locally. If not, it returns an appropriate error code.
- Segment Store delegates request to the appropriate Segment Container instance.
- Segment Container verifies that the Segment belongs to the Segment Container and that the Segment actually exists. If not, it returns an appropriate error code.
- During this process, it also gets an existing Segment ID or assigns a new one (by using the Segment Mapper component).
- Segment Container creates a
StreamSegmentAppendOperationwith the input data and sends it to the Durable Log.
- Segment Container verifies that the Segment belongs to the Segment Container and that the Segment actually exists. If not, it returns an appropriate error code.
- Durable Log takes the Append operation and processes it according to the algorithm described in the Durable Log section.
- Puts it in its operation Queue.
- Operation Processor pulls all operations off the Queue.
- Operation Processor uses the Data Frame Builder to construct Data Frames with the operations it has.
- Data Frame Builder asynchronously writes the Data Frame to the Durable Data Log.
- Upon completion, the following are done in parallel:
- Metadata is updated.
- The operation is added to the Memory Operation Log and Read Index.
- A call that triggered the operation is acked.
- The above process is asynchronous, which means the Operation Processor will have multiple Data Frames in flight (not illustrated). It will keep track of each one's changes and apply or roll them back as needed.
This process applies for every single operation that the Segment Store supports. All modify operations go through the Operation Processor and have a similar path.
Reads¶
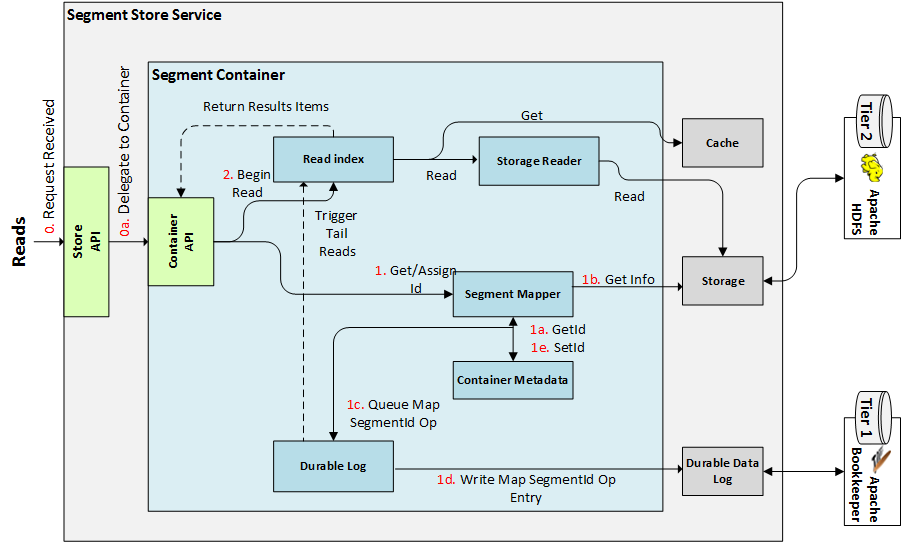
The diagram above depicts these steps (note the step numbers may not match, but the order is the same):
- Segment Store receives read request with params: Segment Name, Read Offset, Max-Length.
- Segment Store determines the Container ID for the given Segment and verifies if it is Leader for given Segment Container. If not, it returns an appropriate error code.
- Segment Store delegates request to the Segment Container instance.
- Segment Container verifies that the Segment belongs to that Container and that it actually exists. If not, it returns an appropriate error code to the client.
- During this process, it also gets an existing Segment ID or assigns a new one (by using the Segment Mapper component).
- Segment Container delegates the request to its Read Index, which processes the read as described in the Read Index section, by issuing Reads from Storage (for data that is not in the Cache), and querying/updating the Cache as needed.
Synchronization with Tier 2 (Storage Writer)¶
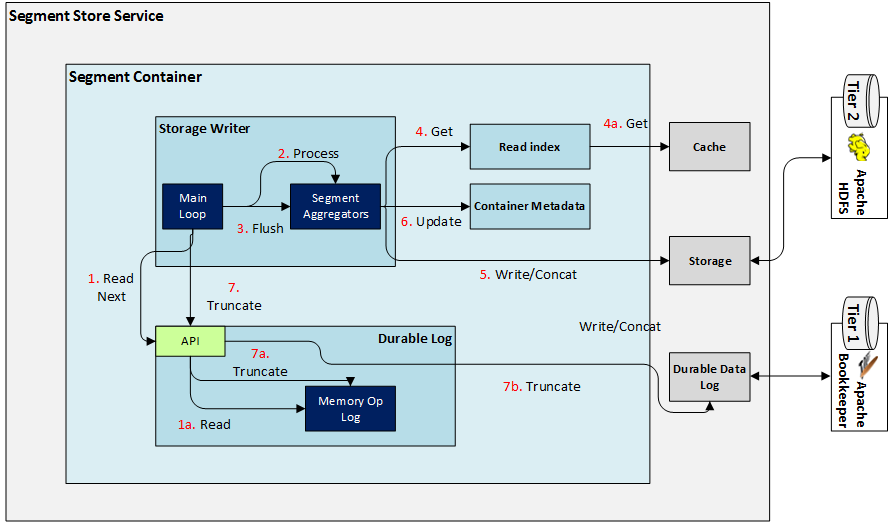
The diagram above depicts these steps (note the step numbers may not match, but the order is the same):
- The Storage Writer's main loop is the sub-component that triggers all these operations.
- Read next operation from the Durable Log (in between each loop, the Writer remembers what the sequence number of the last processed operation was).
- All operations are processed and added to the internal Segment Aggregators (one Aggregator per Segment).
- Eligible Segment Aggregators are flushed to Storage (eligibility depends on the amount of data collected in each aggregator, and whether there are any Seal, Merge or Truncate operations queued up).
- Each time an Append operation is encountered, a trip to the Read Index may be required in order to get the contents of the append.
- After every successful modification (write/seal/concat/truncate) to Storage, the Container Metadata is updated to reflect the changes.
- The Durable Log is truncated (if eligible).
Container Startup (Normal/Recovery)¶
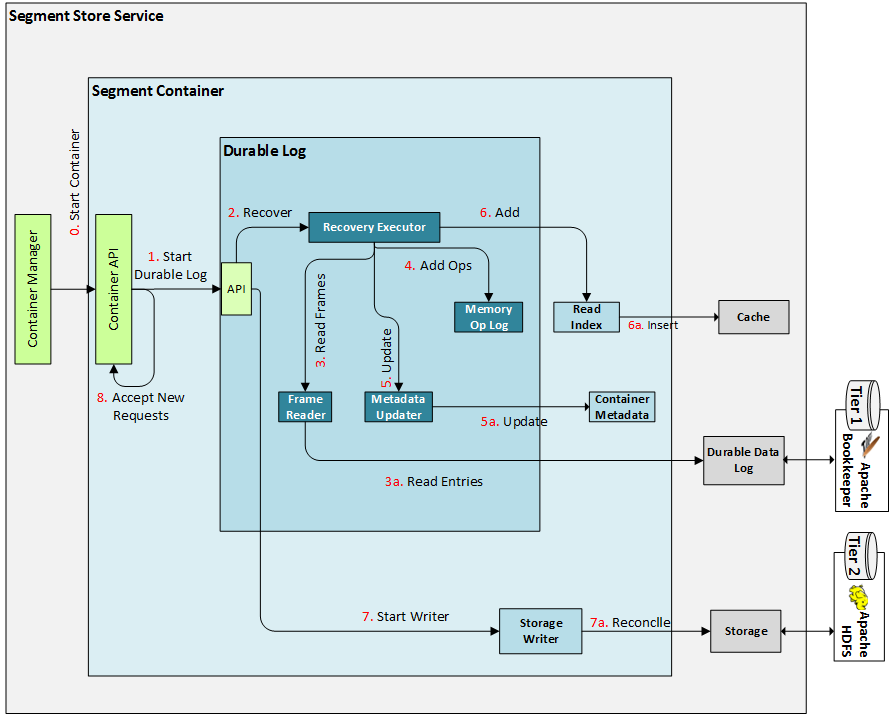
The diagram above depicts these steps (note the step numbers may not match, but the order is the same):
- The Container Manager receives a request to start a Container in this instance of the Segment Store Service.
- It creates, registers, and starts the Container.
- The Container starts the Durable Log component.
- Durable Log initiates the recovery process (coordinated by the Recovery Executor).
- Recovery Executor reads all Data Frames from Durable Data Log.
- Deserialized operations from the read Data Frames are added to the Memory Operation Log.
- The Container Metadata is updated by means of the Operation Metadata Updater (same as the one used inside Operation Processor).
- The Read Index is populated with the contents of those operations that apply to it.
- The Container Starts the Storage Writer.
- The Storage Writer's Main Loop starts processing operations from the Durable Log, and upon first encountering a new Segment, it reconciles its content (and metadata) with the reality that exists in Storage.
- After both the Durable Log and the Storage Writer have started, the Container is ready to start accepting new external requests.